

Another look at comparing task-parallel programming platforms


I’d like to welcome Tsung-Wei (TW) Huang to the ranks of Fastcode contributors.

TW joins me today as we update my post from a few months ago, “Comparing shared-memory platforms for performance engineering.”
Finding performance-engineering El Dorado
When we compare programming platforms, we are trying to choose one that makes it as easy as possible to write good and efficient code. Charles Leiseron posted here that performance is like currency, so we picture our comparison efforts as hacking through the jungle on a quest for El Dorado, the lost city of gold, where money/performance comes freely to anyone who wants it.
Shortly after Bruce’s original post on comparing shared-memory platforms, he learned from Rod Tohid about Thoman et al.’s taxonomy of task-based parallel programming technologies for high-performance computing. Thoman’s taxonomy is more comprehensive than Bruce’s original feature-comparison table, but it’s arguably a bit unwieldy as a tool for hacking through the jungle to El Dorado. So the three of us (Bruce, TW, and Rod) synthesized the two comparison tools into this:
Fastcode’s feature comparison table of task-parallel technology for SPE
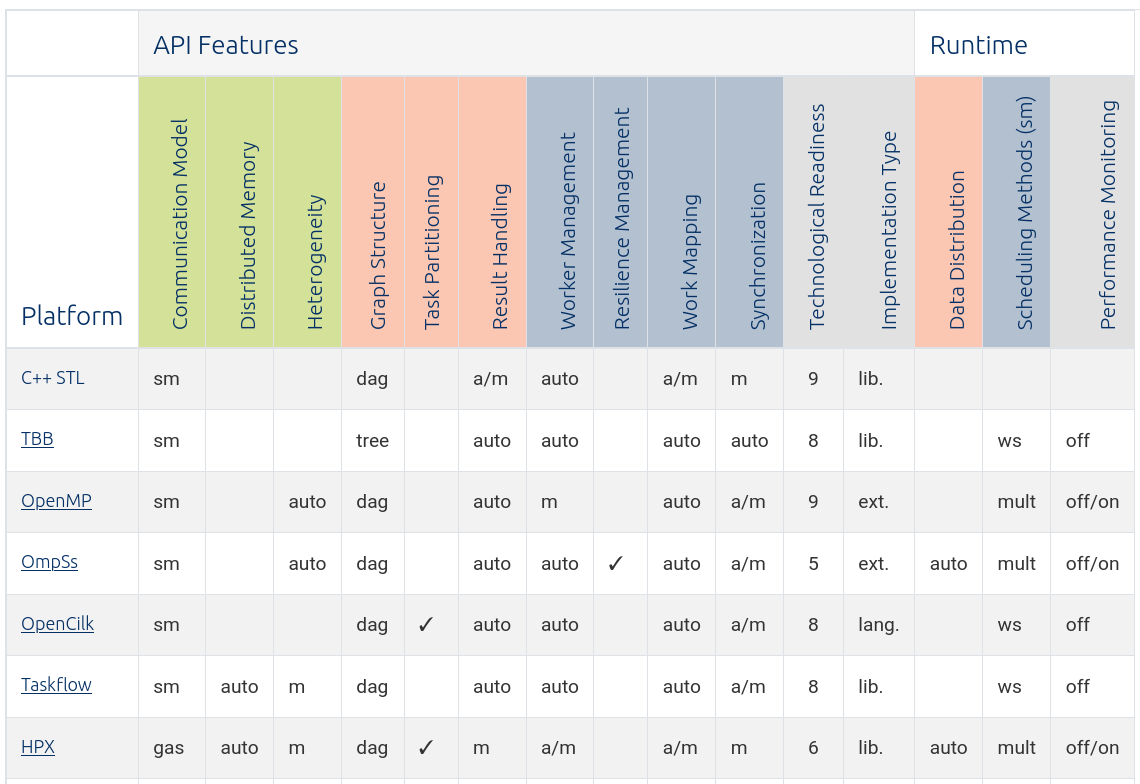
See here for the full table, which includes additional rows for distributed-memory platforms Legion, PaRSEC, Charm++, AllScale, StarPU, Chapel, and X10.
“Searching for El Dorado” meets the actual jungle
Talking with Rod about the ultimate map led to a mini-epiphany for Bruce. The ultimate map might be useful for people who talk about performance engineering, but what about people who actually do performance engineering? We imagine those people—people who improve program performance while simultaneously supporting existing users, architectures, and legacy systems—as more “living in jungle” than “searching for El Dorado.” Here’s how those people might receive our feature-comparison table:
Welcome to the jungle
Tangled constraints are the watered soil that feeds the jungle of actually doing software performance engineering. With that perspective, we shift—
away from a formalized taxonomy of SPE platforms,
towards principled diagnostic questions to help jungle inhabitants find their way to better performance.
Guiding questions
With our shift, we arrive at the following very basic flow chart for choosing your platform for software performance engineering:
Verifying answers
Some people might prefer to approach this search the other way, by verifying the use cases for a pre-selected platform. With that in mind, we close this post with brief reflections on why OpenCilk, or OpenMP, or Taskflow, or HPX might be the right answer for you.
OpenCilk, a fork-join-based extension to LLVM/Clang, is an ideal platform for “going multicore” with an existing serial program, thanks to keywords like
cilk_forthat make it easy to expose logical parallelism that the runtime system will automatically exploit. It provides race detection to ensure that parallelizing your program does not introduce new bugs, and it integrates with popular LLVM/Clang profilers and debuggers.OpenMP, a directive-driven library that extends C/C++ and FORTRAN, is well-suited and popular for parallelizing scientific-computing applications, which typically can be programmed using regular grid communication patterns. By itself, OpenMP is designed for shared memory; but, when paired with MPI, OpenMP is part of one of the world’s most popular platforms for distributed SPE.
Taskflow, a C++ task-parallel library, is designed for shared-memory applications with complex dependency patterns (e.g., task graphs, dynamic control flow). It offers flexibility to customize thread communication behavior.
HPX, an extension to C++ STL, is designed to maximize system throughput by enabling parallelism and concurrency in shared and distributed environments, using the latest C++ standards (without introducing any additional syntax or standard like OpenMP.)
More to come
We will post again soon on this topic, using detailed guiding questions to say more about individual platforms. Below are some questions that we propose to use. What do you think? If you want to update our questions, please comment below or contact us.
Parallelizing an existing serial program for a shared memory architecture
When run on a single processor, how does the performance of your parallelized program compare to the performance of the original serial program?
How much harder is it to debug your parallelized program than to debug the original? Can you use your standard, familiar debugging tools?
Can you maintain just one code base, or must you maintain serial and parallel versions? Do you have to update your program every time the host system gets upgraded?
Application performance
Does the platform address latency or just throughput? What tools are available for detecting performance bottlenecks?
Does the platform allow you to measure the parallelism and scalability of your program?
Does the platform’s scheduler load‐balance irregular applications efficiently to achieve full utilization?
Software reliability
Are there effective debugging tools to identify parallel‐programming errors, such as data‐race bugs?
What changes must you make to your testing processes to ensure that your deployed software is reliable? Can you use your existing unit tests and regression tests?
Development time
How much logical restructuring will your program need?
Can you easily hire or train programmers to use the platform?