

Stinging Stragglers: Accelerating SSSP with Priority-Aware Work Stealing

[With this post, Fastcode welcomes Marco D’Antonio to the ranks of our contributors. We first met Marco one year ago at the Fastcode Programming Challenge, where his team won first place; and we are pleased to feature his work below, in his own words.]
When I started my PhD on “application-aware relaxed synchronization in graph analytics,” I began by looking at classic state-of-the-art shared-memory algorithms. I noticed that a surprising number of them still rely on the Bulk Synchronous Parallel (BSP) model.
In BSP, computation is divided into distinct steps. Threads collaborate to compute a workload and then synchronize—usually via a barrier—before moving to the next step. This isn’t a critique of BSP; it is a valid, elegant approach that allows for parallel primitives that are efficient in both theory and practice.
However, being a bit naïve, I asked myself: “Can we do better?”
Stragglers and Synchronization in SSSP
I started analyzing algorithms for the Single-Source Shortest Path (SSSP) problem.
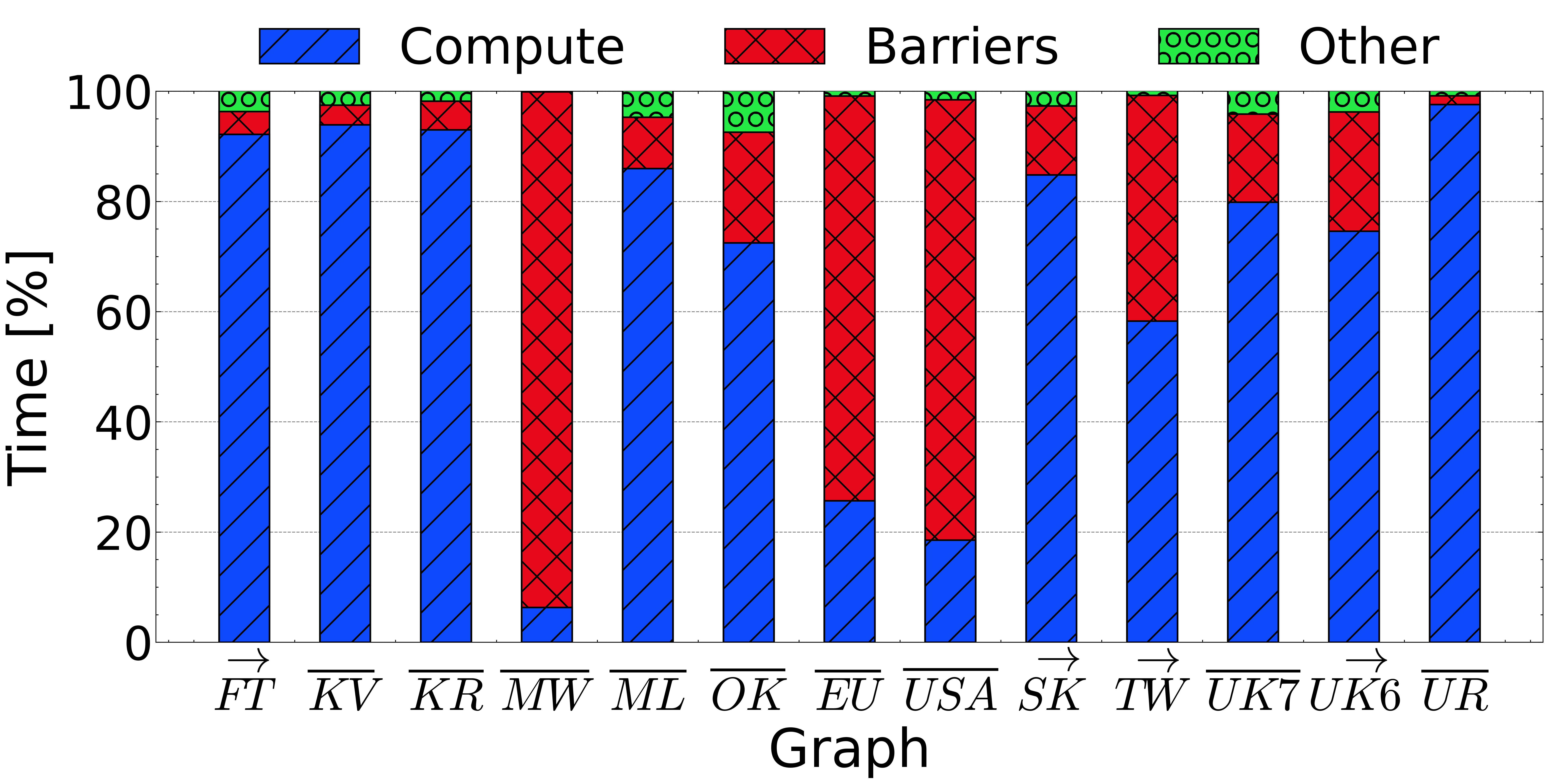
I noticed that for certain graphs, thread synchronization consumed a significant portion of the algorithm execution time. This happens because graph algorithms are often irregular and the workload of each thread can be data dependent. This is the case with SSSP, in which the workload depends on the number of edges a vertex has.
Because some threads are assigned heavier vertices and some threads some lighter ones, the workload varies, and some threads finish early while others struggle with heavy workloads. The result? Fast threads sit idle, waiting at the barrier for the stragglers to finish.
Asynchrony and Work Stealing
My idea was simple: Why wait when you can help?
I wanted to use that idle time to assist the stragglers by taking over some of their workload. At the time, I was working with the GAP Benchmark Suite implementation of SSSP, where threads use a parallel for loop to share work from a shared frontier of vertices. To help straggler threads complete their workload, I needed a dynamic approach: work stealing.
We implemented a work-stealing queue that allowed idle threads to “steal” vertices from busy threads. This is realized by providing each thread with their own work-stealing queue where vertices sit waiting to be retrieved, either by the owner, or by a thief. We also realized we could completely eschew barriers, allowing threads to progress entirely independently.
But here is the plot twist: It didn’t work as well as planned. The culprit was a fundamental characteristic of SSSP: priority ordering.
Parallelism vs Wasted Work
To talk about priority ordering this, we need to discuss the most famous algorithm for SSSP: Dijkstra’s algorithm. It is a simple greedy algorithm that uses a priority queue to process the vertex with the shortest distance at every step. Strictly following these priorities (processing shorter distances first) is crucial for efficiency. If you process a “far away” vertex now, but later find a shorter path to it, you have to re-do that work. That initial effort was wasted.
While Dijkstra is efficient sequentially, it struggles in parallel because a centralized priority queue becomes a bottleneck due to contention. To get around this in parallel settings, most implementations use a flavor of Δ-stepping. This algorithm divides the range of distances into buckets based on a parameter Δ, processing vertices that fall into the same bucket in parallel. This increases parallelism but relaxes the strict ordering of Dijkstra, accepting a small amount of wasted work for a (much) larger gain in performance.
Priority-aware Work Stealing
Going back to our initial barrier-free implementation (also based on Δ-stepping), we realized the flaw was the way we did work-stealing. We tried different approaches for work stealing: random, round-robin, MultiQueues-like but none of these really worked. An idle thread might steal a low-priority vertex from a victim, process it, and generate new work, only to realize later that a high-priority vertex needed to be processed first.
The key insight was to change the stealing logic. Why steal randomly when you can steal high-priority work?
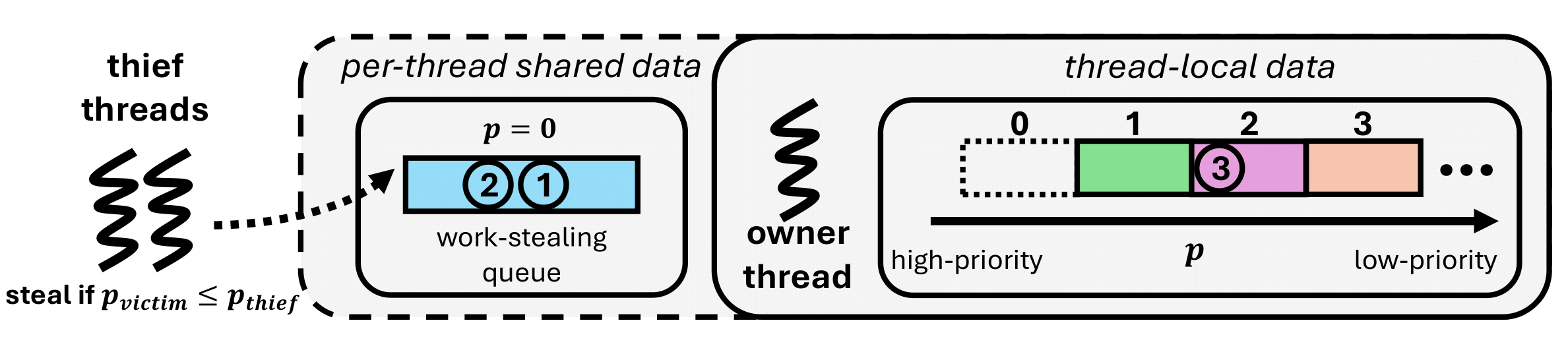
To explain how we do this, we need an itty-bitty amount of technical detail about the data structures each thread uses in our implementation to store vertices:
The work-stealing queue, which represents the bucket the thread is currently working on – since buckets represent ranges of priorities, after processing a vertex, some of their neighbor can re-enter the same bucket.
A thread-local list of buckets, one for every possible priority level (i.e., bucket index), that will store the neighbors of processed vertices, whose priorities are lower than that of the currently processed bucket.
Since threads progress independently now that there are no barriers, threads can be working on different buckets indices, i.e. working on vertices with different priorities. Therefore, once a thread finishes processing the work in their work-stealing queue, it can ask the question: is it better to work on the next bucket available in the thread-local list, or does some other thread need help with higher-priority work?
Therefore, threads will proceed stealing only if their victims have work with a higher priority than their locally available work. This technique – priority-aware work stealing – ensures that threads always gravitate toward the most useful work available in the system.
Combined with full asynchrony and some additional performance engineering, this approach allowed us to outperform all the state-of-the-art algorithms we compared against in our recent paper, “Wasp: Efficient Asynchronous Single-Source Shortest Path on Multicore Systems via Work Stealing”.
The paper also explains the algorithm clearly and has more technical details about the additional optimizations and performance engineering we performed during the implementation of the algorithm, so make sure to take a look!